[Editor’s Note: You can read Reverse Engineering the YouTube Algorithm: Part I right here. You don’t need to read it before reading Part II, but you should check it out at some point. It’s excellent.]
A team of Google researchers presented a paper in Boston, Massachusetts on September 18, 2016 titled Deep Neural Networks for YouTube Recommendations at the 10th annual Association for Computing Machinery conference on Recommender Systems (or, as the cool kids would call it, the ACM’s RecSys ‘16).
This paper was written by Paul Covington (currently a Senior Software Engineer at Google), Jay Adams (currently a Software Engineer at Google), and Embre Sargin (currently a Senior Software Engineer at Google) to show other engineers how YouTube uses Deep Neural Networks for Machine Learning. It gets into some pretty technical, high-level stuff, but what this paper ultimately illustrates is how the entire YouTube recommendation algorithm works(!!!). It gives a careful and prudent reader insight into how YouTube’s Browse, Suggested Videos, and Recommended Videos features actually function.
Subscribe for daily Tubefilter Top Stories
An Engineering Paper On The YouTube Algorithm For Dummies
While it was not necessarily the intent of the authors, it is our belief the Deep Neural paper can be read and interpreted by and for YouTube video publishers. The below is how we (and when I say we, I mean me and my team at my shiny new company Little Monster Media Co.) interpret this paper as a video publisher.
In a previous post I co-wrote here on Tubefilter, Reverse Engineering The YouTube Algorithm, we focused on the primary driver of the algorithm, Watch Time. We looked at the data from our videos on our channel to try to gain insight into how the YouTube algorithm worked. One of the limiting factors to this approach, however, is that it’s coming from a video publisher’s point of view. In an attempt to gain some insight into the YouTube algorithm we asked ourselves and then answered the question, “Why are our videos successful?” We were doing our best with the information we had, but our initial premise wasn’t ideal. And while I stand by our findings 100%, the problem with our previous approach is primarily twofold:
- Looking at an individual set of channel metrics means there’s a massive blind spot in our data, as we don’t have access to competitive metrics, session metrics, and clickthrough rates.
- The YouTube algorithm gives very little weight to video publisher-based metrics. It’s far more concerned with audience and individual-video-based metrics. Or, in laymen’s terms, the algorithm doesn’t really care about the videos you’re posting, but it cares a LOT about the videos you (and everyone else) are watching.
But at the time we wrote our original paper, there had been nothing released from YouTube or Google in years that would shed any light onto the algorithm in a meaningful way. Again, we did what we could with what we had. Fortunately for us though, the paper recently released by Google gives us a glimpse into exactly how the algorithm works and some of its most important metrics. Hopefully this begins to allow us to answer the more poignant question, “Why are videos successful?”
Staring Into The Deep Learning Abyss
The big takeaway from the paper’s introduction is that YouTube is using Deep Learning to power its algorithm. This isn’t exactly news, but it’s a confirmation of what many have believed for some time. The authors make the reveal in their intro:
In this paper we will focus on the immense impact deep learning has recently had on the YouTube video recommendations system….In conjugation with other product areas across Google, YouTube has undergone a fundamental paradigm shift towards using deep learning as a general-purpose solution for nearly all learning problems.
What this means is that with an increasing likelihood there’s going to be no humans actually making algorithmic tweaks, measuring those tweaks, and then implementing those tweaks across the world’s largest video sharing site. The algorithm is ingesting data in real time, ranking videos, and then providing recommendations based on those rankings. So, when YouTube claims they can’t really say why the algorithm does what it does, they probably mean that very literally.
The Two Neural Networks
The paper begins by laying out the basic structure of the algorithm. This is the author’s first illustration:
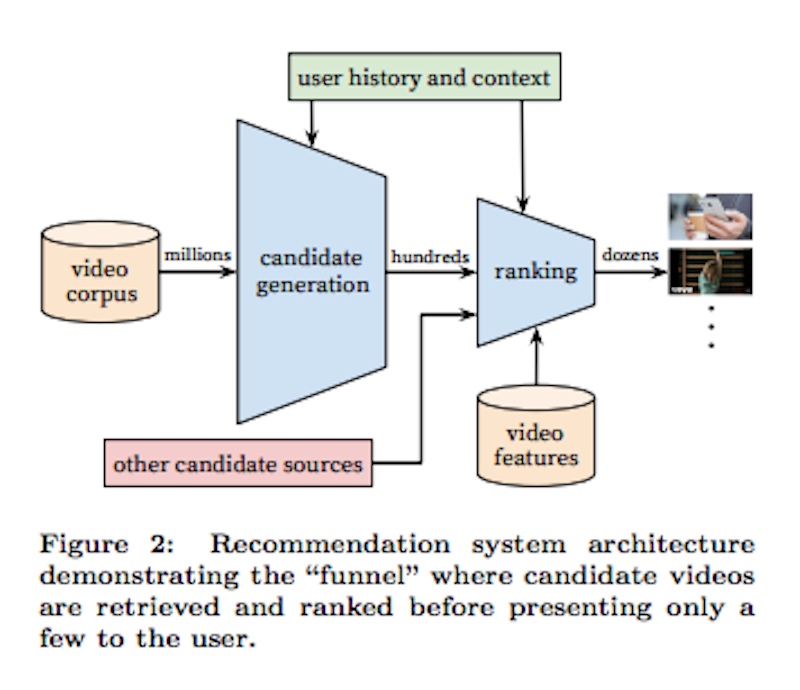
Essentially there are two large filters, with varying inputs. The authors write:
The system is comprised of two neural networks: one for candidate generation and one for ranking.
These two filters and their inputs essentially decide every video a viewer sees in YouTube’s Suggested Videos, Recommend Videos, and Browse features.
The first filter is Candidate Generation. The paper states this is determined by “the user’s YouTube activity history,” which can be read as the user’s Watch History and Watch Time. Candidate Generation is also determined by what other similar viewers have watched, which the authors refer to as Collaborative Filtering. This algorithm decides who’s a similar viewer through “coarse features such as IDs of video watches, search query tokens, and demographics”.
To boil this down, in order for a video to be one of the “hundreds” of videos that makes it through first filter of Candidate Generation, that video must be relevant to the user’s Watch History and it must also be a video that similar viewers have watched.
The second filter is the Ranking filter. The paper goes into a lot of depth around the Ranking Filter and cites a few meaningful factors of which it’s composed. The Ranking filter, the authors write, ranks videos by:
…assigning a score to each video according to a desired objective function using a rich set of features describing the video and user. The highest scoring videos are presented to the user, ranked by their score.
Since Watch Time is the top objective of YouTube for viewers, we have to assume it’s the “desired objective function” referenced. Therefore, the score is based on how well a video, given the various user inputs, is going to be at generating Watch Time. But, unfortunately, it’s not quite that simple. The authors reveal there’s a lot more that goes into the algorithm’s calculus.
We typically use hundreds of features in our ranking models.
How the algorithm ranks videos is where the math gets really complex. The paper also isn’t explicit about the hundreds of factors considered in the ranking models, nor how those factors are weighted. It does cite the three elements mentioned in the Candidate Generation filter, however, (which are Watch History, Search History, and Demographic Inforomation) and several others including “freshness”:
Many hours worth of videos are uploaded each second to YouTube. Recommending this recently uploaded (“fresh”) content is extremely important for YouTube as a product. We consistently observe that users prefer fresh content, though not at the expense of relevance.
One interesting wrinkle the paper notes is that the algorithm isn’t necessarily influenced by the very last thing you watched (unless you have a very limited history). The authors write:
We “rollback” a user’s history by choosing a random watch and only input actions the user took before the held-out label watch.
In a later section of the paper they discuss clickthrough rates (aka CTR) on video impressions (aka Video Thumbnails and Video Titles). It states:
For example, a user may watch a given video with high probability generally but is unlikely to click on the specific homepage impression due to the choice of thumbnail image….Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression.
It’s not a surprise clickthrough rates are called out here. In order to generate Watch Time a video has to get someone to watch it in the first place, and the most surefire way to do that is with a great thumbnail and a great title. This gives credence to many creator’s claims that clickthrough rate are extremely important to a video’s ranking within the algorithm.
YouTube knows that CTR can be exploited so they provide a counterbalance. This paper acknowledges this when it states the following:
Ranking by click-through rate often promotes deceptive videos that the user does not complete (“clickbait”) whereas watch time better captures engagement [13, 25].
While this might seem encouraging, the authors go on to write:
If a user was recently recommended a video but did not watch it then the model will naturally demote this impression on the next page load.
These statements support the idea that if viewers are not clicking a certain video, the algorithm will stop serving that video to similar viewers. There is evidence in this paper that this happens at the channel as well. It states (with my added emphasis):
We observe that the most important signals are those that describe a user’s previous interaction with the item itself and other similar items… As an example, consider the user’s past history with the channel that uploaded the video being scored – how many videos has the user watched from this channel? When was the last time the user watched a video on this topic? These continuous features describing past user actions on related items are particularly powerful…
In addition, the paper notes all YouTube watch sessions are considered when training the algorithm, including those that are not part of the algorithm’s recommendations:
Training examples are generated from all YouTube watches (even those embedded on other sites) rather than just watches on the recommendations we produce. Otherwise, it would be very difficult for new content to surface and the recommender would be overly biased towards exploitation. If users are discovering videos through means other than our recommendations, we want to be able to quickly propagate this discovery to others via collaborative filtering.
Ultimately though, it all comes back to Watch Time for the algorithm. As we saw at the beginning of the paper when it stated the algorithm is designed to meet a “desired objective function,” the authors conclude with “Our Goal is to predict expected watch time,” and “Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression.”
This confirms, once again, that Watch Time is what all of the factors that go into the algorithm are designed to create and prolong. The algorithm is weighted to encourage the greatest amount of time on site and longer watch sessions.
To Recap
That’s a lot to take in. Let’s quickly review.
- YouTube uses three primary viewer factors to choose which videos to promote. These inputs are Watch History, Search History, and Demographic Information.
- There are two filters a video must get through in order to be promoted by way of YouTube’s Browse, Suggested Videos, and Recommended Videos features:
- Candidate Generation Filter
- Ranking Filter
- The Ranking Filter uses the viewer inputs, as well as other factors such as “Freshness” and Clickthrough Rates.
- The promotional algorithm is designed to continually increase watch time on site by continually A/B testing videos and then feeding that data back into the neural networks, so that YouTube can promote videos that lead to longer viewing sessions.
Still Confused? Here’s An Example.
To help explain how this works, let’s look at an example of the system in action.
Josh really likes YouTube. He has a YouTube account and everything! He’s already logged into YouTube when he visits the site one day. And when he does, YouTube assigns three “tokens” to Josh’s YouTube browsing sessions. These three tokens are given to Josh behind the scenes. He doesn’t even know about them! They’re his Watch History, Search History, and Demographic Information.
Now is where the Candidate Generation filter comes into play. YouTube takes the value of those “tokens” and combines it with the Watch History of viewers who like to watch the same kind of stuff Josh likes to watch. What’s left over is hundreds of videos that Josh might be interested in viewing, filtered out from the millions and millions of videos on YouTube.
Next, these hundreds of videos are ranked based on their relevancy to Josh. The algorithm asks and answers the following questions in fractions of a second: How likely is it that Josh will watch the video? How likely is it the video will lead to Josh spending a lot of time on YouTube? How fresh is the video? How has Josh recently interacted with YouTube? Plus hundreds of other questions!
The top ranked videos are then served to to Josh in YouTube’s Browse, Suggested Videos, and Recommended Videos features. And Josh’s decision on what to watch (and what not watch) is sent back into the Neural Network so the algorithm can use that data for future viewers. Videos that get clicked, and keep the user watching for long periods of time, continue to be served. Those that don’t get clicks may not make it through the Candidate Generation filter the next time Josh (or a viewer like Josh) visits the site.
Conclusion
Deep Neural Networks for YouTube Recommendations is a fascinating read. It’s the first real glimpse into the algorithm, directly from source(!!!), that we’ve seen in a very long time. I hope we continue to see more papers like it so publishers can make better choices about what content they create for the platform. And that’s ultimately why I write these blogs in the first place. Making content suited for the platform means creators will generate more views, and therefore more revenue, which ultimately means we can make more and better programming and provide more entertainment for the billions of viewers who rack up significant Watch Time on YouTube each and every month.
 Matt Gielen is the founder and CEO of Little Monster Media Co., a video agency specializing in audience development on YouTube and Facebook. Founded in the summer of 2016 Little Monster has already helped dozens of clients big and small grow their audiences. Formerly, Matt was Vice President of Programming and Audience Development at Frederator Networks where he oversaw the building of the audiences for Cartoon Hangover, Channel Frederator and the Channel Frederator Network.
Matt Gielen is the founder and CEO of Little Monster Media Co., a video agency specializing in audience development on YouTube and Facebook. Founded in the summer of 2016 Little Monster has already helped dozens of clients big and small grow their audiences. Formerly, Matt was Vice President of Programming and Audience Development at Frederator Networks where he oversaw the building of the audiences for Cartoon Hangover, Channel Frederator and the Channel Frederator Network.
And in a personal plug, Matt will be diving into a lot of this and more at his VidCon presentations this year in Amsterdam, Anaheim, and Australia. Hell be exploring what these new findings mean for publishers and – more importantly – how publishers can capitalize on the information this paper has revealed. He’s excited to see you you there.
You can read more of Matt’s articles on Tubefilter here, and follow Matt on Twitter.